
Pattern 4 (Multiple Instance Data)
FLASH animation of Multiple Instance Data pattern
Description
Tasks which are able to execute multiple times within a single case can define data elements which are specific to an individual execution instance.
Example
Each instance of the Expert Assessment task is provided with the case history and test results at commencement and manages its own working notes until it returns a verdict at completion.
Motivation
Where a task executes multiple times, it is useful to be able to define a set of data elements which are specific to each individual execution instance. The values of these elements may be passed to the task instance at commencement and at the conclusion of its execution they can be made available (either on an individual basis or as part of an aggregated data element) to subsequent tasks. There are three distinct scenarios in which a task could be executed more than once:
- Where a particular task is designated as a multiple instance task and once it is enabled, multiple instances of it are initiated simultaneously.
- Where distinct tasks in a process share the same implementation.
- Where a task can receive multiple initiation triggers (i.e. multiple tokens in a Petri-net sense) during the operation of a case.
Overview
Each of these scenarios is illustrated in Figure 5 through process fragments based on the YAWL notation. In the top lefthand diagram, task E illustrates a multiple instance task. In the bottom lefthand diagram, task D corresponds to both an OR-join. When the OR-join construct receives a control flow triggering from any of the incoming arcs, it immediately invokes the associated task. If it receives multiple triggers at distinct points in time, then this results in the task being invoked multiple times. In the righthand diagram, tasks C and E both share the same implementation that is defined by the subworkflow containing tasks X and Y. Further details on YAWL can be found in [AH05].
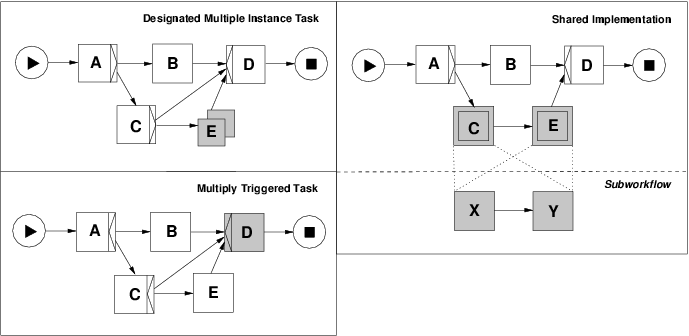
Figure 5: Alternative implementations of multiple instance tasks
Context
There are no specific conditions associated with this pattern.
Implementation
The ability to support distinct data elements in multiple task instances presumes the offering is also able to support data elements that can be bound specifically to individual tasks (i.e. Task Data) in some form. Offerings lacking this capability are unable to facilitate the isolation of data elements between task instances for any of the scenarios identified above. In addition to this, there are also other prerequisites for individual scenarios as described below.
In order to support multiple instance data in the first of the scenarios identified above, the offering must also support designated multiple instance tasks and it must provide facilities for composite data elements (e.g. arrays) to be split up and allocated to individual task instances for use during their execution and for these data elements to be subsequently recombined for use by later tasks.
The second scenario requires the offering to provide task-level data binding and support the capability for a given task to be able to receive multiple triggers. Each of the instances should have a mutually distinct set of data elements which can receive data passed from preceding tasks and pass them to subsequent tasks.
For the third scenario, it must be possible for two or more distinct block tasks to share the same implementation (i.e. the same underlying subprocess) and the offering must support block-level data. Additionally these data elements must be able to be allocated values at commencement of the subprocess and for their values to be passed back to the calling (block) task once the subprocess has completed execution.
Of the various multiple instance scenarios identified, FLOWer provides support for the first of them (footnote 3). Websphere MQ, COSA, XPDL and BPMN can support the second and Websphere MQ, COSA, iPlanet and BPMN directly support the third scenario. UML 2.0 ADs support all three scenarios. Staffware can potentially support the third scenario also, however programmatic extensions would be necessary to map individual instances to distinct case level variables.
Issues
A significant issue that arises for PAIS that support designated multiple instance tasks such as FLOWer involves the partitioning of composite data elements (such as an array) in a way that ensures each task instance receives a distinct portion of the data element that is passed to each of the multiple task instances.
Solutions
FLOWer has a unique means of addressing this problem through mapping objects which allow sections of composite data element in the form of an array (e.g. X[1], X[2] and so on) to be allocated to individual instances of a multiple instance task (known as a dynamic plan). Each multiple task instance only sees the element it has been allocated and each task instance has the same naming for each of these elements (i.e. X). At the conclusion of all of the multiple instances, the data elements are coalesced back into the composite form together with any changes that have been made.
Evaluation Criteria
An offering achieves full support if it has a construct that satisfies the description for the pattern. It achieves a partial support rating if programmatic extensions are required to manage the partitioning and coalescence of individual instances of the multiple instance data element.
Product Evaluation
To achieve a + rating (direct support) or a +/- rating (partial support) the product should satisfy the corresponding evaluation criterion of the pattern. Otherwise a - rating (no support) is assigned.
Product/Language |
Version |
Score |
Motivation |
|---|---|---|---|
| Staffware | 9 | +/- | Only scenerio supported is multiple task triggering but there is not direct means of ensuring data independence of each invocation |
| Websphere MQ Workflow | 3.4 | + | Support for distinct data elements in multiply triggered tasks and tasks with shared sub-workflow decompositions |
| FLOWer | 3.0 | + | Fully supported through dynamic plans |
| COSA | 4.2 | + | Support for distinct data elements in multiply triggered tasks and tasks with shared sub-workflow decompositions |
| XPDL | 1.0 | + | Support for distinct data elements in tasks with shared sub-workflow decompositions |
| BPEL4WS | 1.1 | - | Not supported. Data elements are scoped at case level |
| BPMN | 1.0 | +/- | Two out of three possible scenarios are supported, namely: i) Where a task can be triggered multiple times, e.g., as part of a loop or as a task following a Multiple Merge construct. ii) Where two tasks share the same decomposition. This is supported through the notion of Independent Sub-Processes. iii) Where a task is specifically designated as having multiple instances in the process model is not supported. The lack of any Properties attribute for the MI (in Table 18, MI Loop Activity Attributes), makes it impossible to handle any instance-specific data for the different instances of a task. |
| UML | 2.0 | + | Directly supported through the Expansion Kind and data objects. |
| Oracle BPEL | 10.1.2 | +/- | Partial support dependents on the type of the MI task |
| jBPM | 3.1.4 | - | jBPM lacks any notion of multiple instance tasks hence multiple instances data is not supported. |
| OpenWFE | 1.7.3 | + | OpenWFE supports multiple instance data visibility by the attribute on-value (or on-field-value) specified for a <concurrent-iterator>. It also supports shared implementation of tasks through sub-processes. |
| Enhydra Shark | 2 | + | Enhydra Shark supports shared implementation of tasks (through subflows). |
Summary of Evaluation
+ Rating |
+/- Rating |
|---|---|
|
|