
Pattern 1 (Task Data)
FLASH animation of Task Data pattern
Description
Data elements can be defined by tasks which are accessible only within the context of individual execution instances of that task.
Example
The working trajectory variable is only used within the Calculate Flight Path task.
Motivation
To provide data support for local operations at task level. Typically these data elements will be used to provide working storage during task execution for control data or intermediate results in the manipulation of production data.
Overview
Figure 2 illustrates the declaration of a task data element (variable X in task B) and the scope in which it can be utilised (shown by the shaded region and the use() function). Note that it has a distinct existence (and potential value) for each instance of task B (i.e. in this example it is instantiated once for each process instance since task B only runs once within each process).
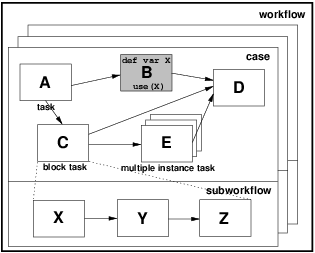
Figure 2: Task level data visibility
Context
There are no specific context conditions associated with this pattern.
Implementation
The implementation of task data takes one of two forms - either data elements are defined as parameters to the task making them available for use within the task or they are declared within the definition of the task itself. In either case, they are bound in scope to the task block and have a lifetime that corresponds to that of the execution of an instance of that task. COSA and BPMN directly support the notion of task data. Websphere MQ, iPlanet and UML 2.0 ADs provide indirect support allowing task data to be defined in the implementations of individual tasks. Similarly FLOWer and BPEL provide indirect support by allowing data elements with greater scope to have their visibility restricted to a single task.
Issues
One difficulty that can arise is the potential for a task to declare a data element with the same name as another data element declared elsewhere (either within another task or at a different level within the process hierarchy (e.g. block, case, global) that can be accessed within the task. This phenomenon is often referred to as "name clash".
The second issue that may require consideration can arise where a task is able to execute more than once (e.g. in the case of a multi-merge [AHKB03]). When the second (or later) instance commences, should the data elements contain the values from the first instance or should they be re-initialised.
Solutions
The first issue can be addressed through the use of a tight binding approach at task level restricting the use of data elements within the task to those explicitly declared by the task itself and those which are passed to the task as formal parameters. All of these data element names must be unique within the context of the task.
An alternative approach is employed in BPEL, which only allows access to the data element with the innermost scope in the event of name clashes. Indeed, this approach is proposed as a mechanism of "hiding" data elements from outer scopes by declaring another with the same name at task level.
The second issue is not a major consideration for most offerings which initialise data elements at the commencement of each task instance. One exception to this is FLOWer which provides the option for a task instance which comprises part of a loop in a process to either refresh data elements on each iteration or to retain their values from the previous instance (in the preceding or indeed any previous loop iteration).
Evaluation Criteria
An offering achieves full support if it has a construct that satisfies the description for the pattern. It achieves partial support rating if the scope of the data elements cannot be restricted to a single task or if the data elements are declared in programmatic extensions to the task.
Product Evaluation
To achieve a + rating (direct support) or a +/- rating (partial support) the product should satisfy the corresponding evaluation criterion of the pattern. Otherwise a - rating (no support) is assigned.
Product/Language |
Version |
Score |
Motivation |
|---|---|---|---|
| Staffware | 9 | - | Not supported |
| Websphere MQ Workflow | 3.4 | +/- | Indirectly supported by 3GL program implementations |
| FLOWer | 3.0 | +/- | Use of restricted option allows update of data element to be limited to single step but other steps can view data value. |
| COSA | 4.2 | + | Directly supported by (non-persistent) STD attributes at the activity level |
| XPDL | 1.0 | - | Only workflow processes can have data elements |
| BPEL4WS | 1.1 | +/- | Scopes provide a means of limiting the visibility of variables to smaller blocks approaching task level binding |
| BPMN | 1.0 | + | The smallest operational unit in a BPMN diagram is Task. Task data is defined through the attribute Properties of a Task. The Properties defined for a Task are local and can only be used within the Task. |
| UML | 2.0 | +/- | Indirectly supported where a local action language is utilised which provides action-specific variables |
| Oracle BPEL | 10.1.2 | +/- | A task must be wrapped into a scope |
| jBPM | 3.1.4 | +/- | In jBPM due to the fact that task variables are mapped to process variables on a one-one basis and the inherent difficulty of defining task variables that do not strictly correspond to existing process variables, the Task Data pattern is not considered to be supported. The Node construct provides the possibility to introduce custom code. Local task data can then be defined and used in such a code. Therefore the support for this pattern is ranked as partial. |
| OpenWFE | 1.7.3 | - | OpenWFE does not support task data. |
| Enhydra Shark | 2 | +/- | Enhydra Shark does not support task data. (Only workflows can have data elements.) It is, however, possible to define Java Script procedures as tasks. In such procedures local data (e.g., loop counters) can be defined. Hence, due to the programmatic extension needed, task data is considered as partially supported. |
Summary of Evaluation
+ Rating |
+/- Rating |
|---|---|
|
|